Django 一覧画面と詳細画面の作成
初めに
前回に続いて本棚アプリケーションの作成を行いました。今回は一覧画面と詳細画面を作成しました。
これに対して行った具体的な手順をまとめます。
nissin-geppox.hatenablog.com
概要
- 一覧画面の設定
- 一覧画面のhtmlの作成
- 詳細画面の設定
- 詳細画面のhtmlの作成
一覧画面の設定
まず、一覧画面にアクセスするためのルーティング設定を行いました。
ルーティング設定としてurls.pyに以下のようなコードを追加しました。
from django.urls import path from . import views urlpatterns = [ path('book/', views.ListBookView.as_view()) ]
次に、以下のようにviews.pyに一覧表示用のclassを作成しました。
from django.shortcuts import render from django.views.generic import ListView from .models import Book class ListBookView(ListView): template_name = 'book/book_list.html' model = Book
一覧画面のhtmlの作成
一覧画面用のhtmlファイルを作成しました。
まず、以下のコマンドよりhtml用のディレクトリとhtmlファイルを生成しました。
$ cd book $ mkdir templates $ cd templates $ mkdir book $ cd book $ touch book_list.html
続いて、生成したbook_list.htmlに以下のコードを追加しました。
{% for item in object_list %}
<ul>
<li>{{ item.title }}</li>
<li>{{ item.text }}</li>
<li>{{ item.category }}</li>
</ul>
{% endfor %}
最後に、以下のコマンドよりサーバーを起動し、作成したhtmlファイルが表示されるかどうかを確認しました。
$ python3 manage.py runserver
ページは以下のように表示されました。
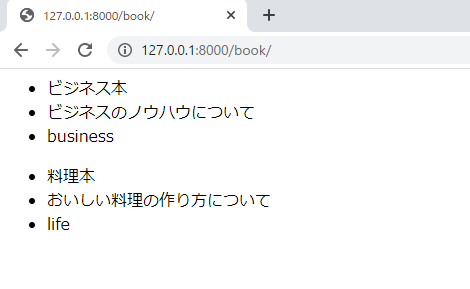
上の画像より正しく表示されることを確認することができました。
詳細画面の設定
まず、詳細画面にアクセスするためのルーティング設定を行いました。
ルーティング設定としてurls.pyに以下のようなコードを追加しました。
from django.urls import path from . import views urlpatterns = [ path('book/', views.ListBookView.as_view()), path('book/<int:pk>/detail/', views.DetailBookView.as_view()), ]
次に、以下のようにviews.pyに詳細画面用のclassを作成しました。
from django.shortcuts import render from django.views.generic import ListView, DetailView from .models import Book class ListBookView(ListView): template_name = 'book/book_list.html' model = Book class DetailBookView(DetailView): template_name = 'book/book_detail.html' model = Book
詳細画面のhtmlの作成
詳細画面のhtmlファイルを作成しました。
まず、以下のコマンドよりhtmlファイルを生成しました。
$ touch book/templates/book/book_detail.html
続いて、生成したbook_detail.htmlに以下のコードを追加しました。
{{ object.category }}
{{ object.title }}
{{ object.text }}
最後に、サーバーを起動し、URLからidが2の記事を指定し、作成したhtmlファイルが表示されるかどうかを確認しました。
ページは以下のように表示されました。
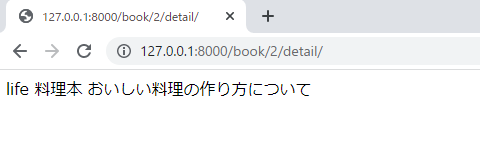
上の画像より、idを設定することにより、指定した記事のみを表示することができました。
Django 初期設定とmodelの作成
初めに
今回から実際に本のタイトルと概要、カテゴリを整理する”本棚アプリケーション”を作成します。それに伴い、初期設定とデータベースのためのモデルを作成します。
これに対して行った具体的な手順をまとめます。
概要
- 仮想環境の構築とDjangoのインストール
- プロジェクトのアプリとベースの作成
- models.pyの作成
- データベースへの反映
- 管理画面でユーザテーブルを確認
仮想環境の構築とDjangoのインストール
まず、以下のコマンドを用いてプロジェクトファイルの作成と仮想環境の構築を行いました。
$ mkdir project3 $ cd project3 $ python3 -m venv .env $ source .env/bin/activate
続いて、以下のコマンドよりDjangoをインストールします。
$ pip install django==3.2
プロジェクトのアプリとベースの作成
初めに、以下のコマンドよりプロジェクトとアプリケーションを作成しました。
また、プロジェクト名は"bookproject"、アプリケーション名は"book"としました。
$ django-admin startproject bookproject $ cd bookproject $ python3 manage.py startapp book
次にプロジェクトのurls.pyからアプリケーションのurls.pyを呼び出すためにプロジェクトのurls.pyを以下のようにしました。
from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('book.urls')) ]
続いて、setting.pyに以下のコードを追加して、プロジェクトとアプリケーションの紐づけを行いました。
# 一部省略 # Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'book.apps.BookConfig' ] MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] ROOT_URLCONF = 'bookproject.urls' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [BASE_DIR / 'templates'], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ]
次に、以下のコマンドよりbookディレクトリ内にもurls.pyを作成しました。
$ touch urls.py
最後に作成したurls.pyに以下のコードを追加しました。
urlpatterns = []
models.pyの作成
ここからはデータベースを構築するためのmodels.pyを作成していきます。
今回はテーブル"Book"と"title"、"text"、"category"の3つのデータを作成しました。作成したmodels.pyは以下のようになりました。
from django.db import models CATEGORY = (('business', 'ビジネス'), ('life', '生活'), ('other', 'その他')) class Book(models.Model): title = models.CharField(max_length=100) text = models.TextField() category = models.CharField( max_length=100, choices = CATEGORY )
データベースへの反映
作成したmodels.pyをもとにデータベースを構築しました。構築には以下のコマンドを使用しました。
$ python3 manage.py makemigrations
コマンドの実行に成功するとターミナルに以下のように出力されます。

上の画像より、modelが正常に生成されていることがわかります。また、実験で作成したSampleModelが削除されていることも確認することができました。
続いて、以下のコマンドよりデータベースに反映させました。
$ python3 manage.py migrate
このコマンドによりターミナルに以下に出力されました。

上の画像より、正常にデータベースに反映されたことを確認することができました。
ここで、作成したデータベースを管理画面より確認しました。
まず、以下のコマンドよりサーバーを起動しました。
$ python3 manage.py runserver
次にurlより管理画面にアクセスし、データベースを確認しました。
以下の画像は管理画面の様子です。

また、管理画面より2つのデータを入力しました。

上記の画像より2つのデータがあることは確認できますが、どのようなデータかを確認することができません。よって、models.pyに以下のようにコードを追加しました。
from django.db import models CATEGORY = (('business', 'ビジネス'), ('life', '生活'), ('other', 'その他')) class Book(models.Model): title = models.CharField(max_length=100) text = models.TextField() category = models.CharField( max_length=100, choices = CATEGORY ) def __str__(self): return self.title
変更後の管理画面は以下のようになりました。

上の画像より、変更によりタイトルを確認することができるようになりました。
Django サーバーの立ち上げと簡単な文字の表示
初めに
前回作成した仮想環境とインストールしたDjangoをもとに、ローカルサーバーを立ち上げました。
また、URLを設定し、Web上に簡単な文字を表示するようにしました。
これに対して、行った具体的な手順をまとめます。
概要
- プロジェクトの作成
- サーバーの立ち上げ
- urls.pyファイルの変更
- viewファイルの作成
プロジェクトの作成
前回作成したproject2ディレクトリにDjangoプロジェクトを作成しました。
また、プロジェクト名はhelloworldprojectとしました。
プロジェクトの作成は以下のコマンドより行うことができます。
$ django-admin startproject helloworldproject
実行が完了するとproject2ディレクトリ内に新たにhelloworldprojectという名のディレクトリが生成されます。
このディレクトリ内にはWebアプリケーションを動作させるにあたり必要なファイルが自動で生成されます。
以下の画像はこのコマンドにより実際にディレクトリが生成されたときの様子です。

サーバーの立ち上げ
サーバーの立ち上げはhelloworldprojectディレクトリ内に生成されたmanage.pyを用いることにより行うことができます。
まず、以下のコマンドよりmanage.pyが存在するディレクトリに移動します。
$ cd helloworldproject/
次に以下のコマンドよりサーバーを立ち上げます。
$ python3 manage.py runserver
このコマンドを実行するとターミナルに以下のような情報が表示されます。

ターミナル内には立ち上げたサーバーにアクセスするためのアドレスが表示されています。
次の画像はウェブブラウザからこのアドレスにアクセスしたときの様子です。

画像より正常にサーバーを立ち上げることができました。
urls.pyファイルの変更
Djangoではプロジェクトを作成した段階で管理画面が用意されています。
この画面にアクセスするためには事前にデータベースを作成する必要があります。
データベースの作成は次のコマンドより行うことができます。
$ pythonm3 manage.py migrate
このコマンドを実行すると以下のような画面がターミナル上に表示されます。

次に以下のコマンドよりサーバーを立ち上げます。
$ python3 manage.py runserver
管理画面にはサーバーを立ち上げた際に表示されたURLに加えて/admin/を追加することによりアクセスすることができます。
次の画像は管理画面にアクセスした様子です。

次にurls.pyを以下の画像の赤下線のように変更しました。
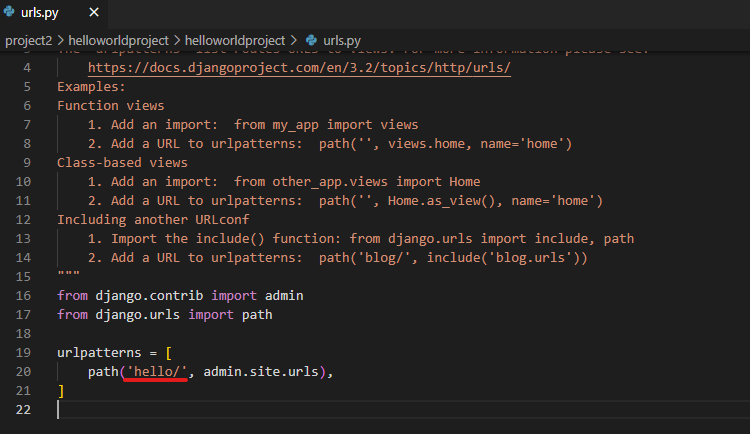
これにより、ターミナルに表示されたURLに加え/hello/を追加することにより管理画面にアクセスすることができるようになりました。
次の画像は管理画面にアクセスした様子です。

先ほどの/admin/でアクセスしたときと結果は変わりません。
一方、urls.pyへの変更後に/admin/でアクセスしたときは以下のようになりました。

"Page not found"と表示され管理画面へアクセスすることができませんでした。
これは、urls.pyの変更によりファイルにアクセスするためのURLが変更されたからです。
viewファイルの作成
Web上で文字を表示させるためのviewファイルを作成します。
viewファイルは以下のように作成しました。
from django.http import HttpResponse def helloworldfunc(request): responseobject = HttpResponse('<h1>hello world</h1>') return responseobject
次に、このviewファイルに合わせてurls.pyを以下のように変更しました。
from django.contrib import admin from django.urls import path from .views import helloworldfunc urlpatterns = [ path('admin/', admin.site.urls), path('helloworldurl/', helloworldfunc), ]
最後に、サーバーを立ち上げ結果を確認しました。

画像より"hello world"という文字列をWeb上に出力することができました。
仮想環境の構築とDjangoのインストール
Linux環境のパッケージのアップデート
仮想環境を構築する前にパッケージマネージャをアップデートしました。
アップデートには以下の2つのコマンドを実行しました。
$ sudo apt update
$ sudo apt upgrade
venvを用いた仮想環境の構築
仮想環境の構築にはAWSでのクラウド開発の際にも用いたvenvを使用します。
仮想環境の作成には以下のコマンドを実行します。また、仮想環境の名前は.envとしました。
$ python3 -m venv .env
仮想環境の立ち上げ
仮想環境の立ち上げは以下のコマンドより行うことができます。
$ source .env/bin/activate
仮想環境の立ち上げに成功するとターミナル上のユーザネームの左に"(.env)"が表示されます。
以下の画像は実際に仮想環境を立ち上げたときのターミナルの様子です。
![]()
画像より仮想環境に入れていることが確認できました。
Djangoのインストール
まず、先ほど同様、ディレクトリ上に仮想環境を作成します。
以下のコマンドよりディレクトリを作成し移動しました。
$ mkdir project2 $ cd project2
次に仮想環境の作成と立ち上げを行います。
$ python3 -m venv .env $ source .env/bin/activate
最後に以下のコマンドよりDjangoをインストールしました。
また、バージョンは3.2をインストールしました。
$ pip install django==3.2
以下の画像はDjangoをインストールする際のターミナルの様子です。

画像より、Djangoを正常にインストールできたことを確認することができました。
Djanmgoの環境構築
はじめに
前回までは主にAWSに関しての学習を行ってきました。
今回からはWebフレームワークに関する学習を進めていきます。
学習するフレームワークはDjangoを選択しました。
今回はDjangoでWeb開発を行うための環境構築を行いました。
概要
Djangoで開発するうえで必要な環境構築は以下の通りです。
- Pythonのインストール
- WSL2のインストール
- Linuxディストリビューションのインストール
- Visual Studio Codeのインストール
- Visual Studio CodeとLinux仮想環境の接続
Pythonのインストール
通常であれば構築した仮想環境上でインストールする必要がありますが以降インストールするLinuxディストリビューションであるUbuntuにはすでにPythonがインストールされているため特別に行うことはありません。
WSL2のインストール
WSL2はAWSを動作させる際にも用いたLinux仮想環境です。よって、以下の記事ですでにインストールは完了しています。
nissin-geppox.hatenablog.com
Linuxディストリビューションのインストール
LinuxディストリビューションとしてUbuntuを使用します。よって、WSL2同様、AWSの環境構築の際にすでにインストールしています。具体的なインストール手順は上記の記事を参照してください。
Visual Studio Codeのインストール
通常、Ubuntuで開発を進める場合はLinux用のエディタ(vimやemacus)を用いてプログラミングを行いますが、今回は統合開発環境であるVisual Studio Codeを用いて開発を行います。
Visual Studio Codeは以下のURLよりダウンロードすることができます。
https://code.visualstudio.com/
Visual Studio CodeとLinux仮想環境の接続
ここではVisual Studio Code上でUbuntuを操作するための環境を構築します。具体的にはVisual Studio Codeの拡張機能である「Remote - WSL」をインストールします。
これにより、Linux環境でもVisual Studio Codeを用いることができるようになります。
1.「Remote - WSL」を検索し拡張機能をインストールする。
2.左下の赤下線部分をクリックし、上部の緑下線部分を選択する。

3.表示されたLinuxディストリビューションを選択する。(今回であればUbuntuが表示されます。)
4.左下の赤下線部分を確認しLinux仮想環境と接続されたことを確認する。

動作確認
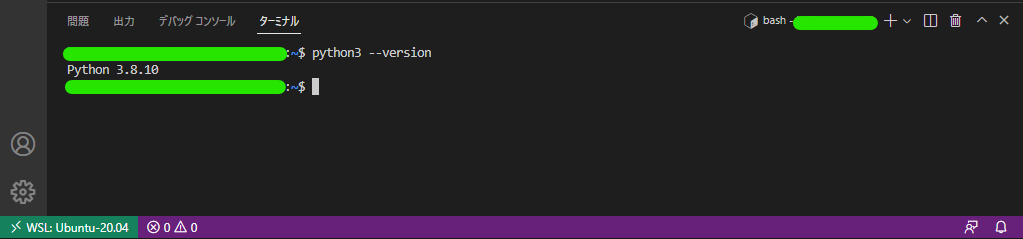
仮想環境と接続されたVisual Studio Codeのターミナル上で以下のコマンドを入力し、Pythonのバージョンを確認しました。
$ python3 --version
結果は下記の画像のようになりました。
boto3を用いたDynamoDBの操作(3/3)
この記事は前回のboto3ライブラリを用いたDynamoDBの操作の続きです。
nissin-geppox.hatenablog.com
nissin-geppox.hatenablog.com
DynamoDBのバックアップ
ここではDynamoDBのバックアップを作成しました。
また、作成したバックアップから復元を行いました。
以降、実際のコードと出力を示します。
まず、DynamoDBのclient()オブジェクトを作成しました。
入力
client = session.client("dynamodb")
次に、create_buckup()関数を用いてバックアップを作成しました。
入力
resp = client.create_backup(
TableName=table_name,
BackupName=table_name + "-Backup"
)
backup_arn = resp["BackupDetails"]["BackupArn"]
print(backup_arn)
出力
arn:aws:dynamodb:ap-northeast-1:093695845064:table/Cov19VaccinationDb-Cov19VaccinationTable07030B40-1T7E4C93IZMX3/backup/01653210567516-466055b6
この出力は作成したバックアップを指し示す固有のIDです。
続いて、作成したバックアップの情報を取得しました。
入力
resp = client.describe_backup(BackupArn=backup_arn) pprint(resp["BackupDescription"]["BackupDetails"])
出力
{'BackupArn': 'arn:aws:dynamodb:ap-northeast-1:093695845064:table/Cov19VaccinationDb-Cov19VaccinationTable07030B40-1T7E4C93IZMX3/backup/01653210567516-466055b6',
'BackupCreationDateTime': datetime.datetime(2022, 5, 22, 18, 9, 27, 516000, tzinfo=tzlocal()),
'BackupName': 'Cov19VaccinationDb-Cov19VaccinationTable07030B40-1T7E4C93IZMX3-Backup',
'BackupSizeBytes': 0,
'BackupStatus': 'AVAILABLE',
'BackupType': 'USER'}
この出力結果より、BuckupStatusがAVAILABLEとなっておりバックアップが使用可能なことを確認することができました。
次に、バックアップの復元を行うにあたって、本体のデータベースの要素の書き換えを行います。
ここではタラオフグタさんのageの属性を4に書き換えました。
入力
resp = table.update_item(
Key={"username": "tarao_huguta", "dose": 1},
UpdateExpression="SET age = :val1",
ExpressionAttributeValues={
":val1": 4
}
)
resp = table.get_item(
Key={"username": "tarao_huguta", "dose": 1},
)
pprint(resp["Item"]["age"])
出力
Decimal('4')
出力結果より、正常にageの属性を書き換えることができました。
続いて、書き換えを行う前に作成したバックアップデータを用いて復元を行いました。
入力
resp = client.describe_table(TableName=table_name + "-restored") pprint(resp["Table"]["TableStatus"])
出力
'ACTIVE'
この処理は数分時間が必要でした。処理中の出力は'CREATING'と表示され、処理が完了すると'ACTIVE'に遷移しました。
次に、復元したテーブルの情報を読み込みました。
入力
restored_table = ddb.Table(restored_table_name)
resp = restored_table.get_item(
Key={"username": "tarao_huguta", "dose": 1},
)
pprint(resp["Item"]["age"])
出力
Decimal('3')
この出力結果より、書き換え前のage属性の値に戻っており、データの復元に成功したことを確認できました。
最後に復元されたテーブルと不要になったバックアップを削除しました。
入力
resp = restored_table.delete() resp = client.delete_backup(BackupArn=backup_arn)
スタックの削除
スタックの削除は以下のコマンドより行うことができます。
$ cdk destroy
boto3を用いたDynamoDBの操作(2/3)
この記事は前回のboto3ライブラリを用いたDynamoDBの操作の続きです。
nissin-geppox.hatenablog.com
QueryとScan
ここでは、Batch writeを用いて複数の要素を一度に書き込みました。
また、書き込んだ要素をQueryやScanを用いて探索しました。
以降、実際のコードと出力を示します。
まず、必要なライブラリをインポートし、Batch writeでテーブルに要素を書き込みました。
入力
import json with open("data.json", "r") as f: data = json.load(f) with table.batch_writer() as batch: for d in data: batch.put_item(Item=d)
次に、用意したテーブルに対してpartition keyを用いてQueryを実行しました。
入力
from boto3.dynamodb.conditions import Key, Attr resp = table.query( KeyConditionExpression=Key('username').eq('namihei_isono') ) pprint(resp.get("Items"))
出力
[{'age': Decimal('54'),
'date': '2021-07-25T10:00:00',
'dose': Decimal('1'),
'first_name': 'Namihei',
'last_name': 'Isono',
'prefecture': 'Chiba',
'status': 'completed',
'username': 'namihei_isono'},
{'age': Decimal('54'),
'date': '2021-08-20T10:00:00',
'dose': Decimal('2'),
'first_name': 'Namihei',
'last_name': 'Isono',
'prefecture': 'Chiba',
'status': 'completed',
'username': 'namihei_isono'}]
この出力結果より、partition keyであるusernameがnamihei_isonoという値を持つ要素を探し出すことができました。
次に、"一回目のワクチンのデータ"を指定してQueryを実行しました。
入力
resp = table.query(
KeyConditionExpression=Key("username").eq("namihei_isono") & Key('dose').eq(1)
)
pprint(resp.get("Items"))
出力
[{'age': Decimal('54'),
'date': '2021-07-25T10:00:00',
'dose': Decimal('1'),
'first_name': 'Namihei',
'last_name': 'Isono',
'prefecture': 'Chiba',
'status': 'completed',
'username': 'namihei_isono'}]
この出力結果より、正しい要素を探し出すことができました。
次に、ageの属性を用いてQueryを実行しました。
入力
resp = table.query(
IndexName="ItemsByAge",
KeyConditionExpression=Key('age').eq(11),
)
pprint(resp.get("Items"))
出力
[{'age': Decimal('11'),
'date': '2021-07-20T10:00:00',
'dose': Decimal('1'),
'first_name': 'Katsuo',
'last_name': 'Isono',
'prefecture': 'Gunma',
'status': 'reserved',
'username': 'katsuo_isono'}]
この出力結果より、11歳のage属性をもつ要素を探し出すことができました。
また、prefectureの属性を用いてQueryを実行しました。
入力
resp = table.query(
IndexName="ItemsByPrefecture",
KeyConditionExpression=Key('prefecture').eq("Tokyo"),
)
pprint(resp.get("Items"))
出力
[{'age': Decimal('3'),
'date': '2021-07-20T10:00:00',
'dose': Decimal('1'),
'first_name': 'Tarao',
'last_name': 'Huguta',
'prefecture': 'Tokyo',
'status': 'reserved',
'username': 'tarao_huguta'},
{'age': Decimal('28'),
'date': '2021-07-20T10:00:00',
'dose': Decimal('1'),
'first_name': 'Huguta',
'last_name': 'Masuo',
'prefecture': 'Tokyo',
'status': 'reserved',
'username': 'masuo_huguta'}]
この出力結果より、住所が東京にある要素を2つ探し出すことができました。
次に、検索条件を指定せずにScanを実行した。
入力
resp = table.scan() items = resp.get("Items") print("Number of items:", len(items))
出力
Number of items: 8
この出力結果より、要素が8個あることが確認できました。
また、Scanは一度に1MBのデータを探索し、上限に達した時点のデータをユーザーに戻します。よって、1MBを超えるデータを探索するには以下の入力のようにLastEvakuatedKeyのような変数を設け、再帰的に探索を実行する必要があります。
入力
resp = table.scan() items = resp.get("Items") while resp.get("LastEvaluatedKey"): resp = table.scan(ExclusiveStartKey=r["LastEvaluatedKey"]) items.extend(resp["Items"]) print("Number of items", len(items))
出力
Number of items 8
出力結果は、先ほどの探索結果と同じになります。
次に、Scanを用いて条件を満たす要素の探索を行った。
入力
resp = table.scan(
FilterExpression=Attr('age').lt(27)
)
pprint(resp.get("Items"))
出力
[{'age': Decimal('9'),
'date': '2021-07-20T10:00:00',
'dose': Decimal('1'),
'first_name': 'Wakame',
'last_name': 'Isono',
'prefecture': 'Saitama',
'status': 'reserved',
'username': 'wakame_isono'},
{'age': Decimal('3'),
'date': '2021-07-20T10:00:00',
'dose': Decimal('1'),
'first_name': 'Tarao',
'last_name': 'Huguta',
'prefecture': 'Tokyo',
'status': 'reserved',
'username': 'tarao_huguta'},
{'age': Decimal('11'),
'date': '2021-07-20T10:00:00',
'dose': Decimal('1'),
'first_name': 'Katsuo',
'last_name': 'Isono',
'prefecture': 'Gunma',
'status': 'reserved',
'username': 'katsuo_isono'}]
この出力結果より、27歳以下の要素を探し出すことができました。
次に、dateの属性を用いて特定の日時の一覧を取得しました。
入力
resp = table.scan(
FilterExpression=Attr('date').begins_with("2021-07-25"),
)
pprint(resp.get("Items"))
出力
[{'age': Decimal('54'),
'date': '2021-07-25T10:00:00',
'dose': Decimal('1'),
'first_name': 'Namihei',
'last_name': 'Isono',
'prefecture': 'Chiba',
'status': 'completed',
'username': 'namihei_isono'}]
この出力結果より、日時が2021-07-25である要素を探し出すことができました。
最後に、要素の一部の属性を取り出しました。
今回はprefecture属性のみを返すようにしました。
入力
resp = table.scan(
ProjectionExpression="first_name, prefecture"
)
pprint(resp.get("Items"))
出力
[{'first_name': 'Wakame', 'prefecture': 'Saitama'},
{'first_name': 'Namihei', 'prefecture': 'Chiba'},
{'first_name': 'Namihei', 'prefecture': 'Chiba'},
{'first_name': 'Huguta', 'prefecture': 'Tokyo'},
{'first_name': 'Hune', 'prefecture': 'Chiba'},
{'first_name': 'Hune', 'prefecture': 'Chiba'},
{'first_name': 'Tarao', 'prefecture': 'Tokyo'},
{'first_name': 'Katsuo', 'prefecture': 'Gunma'}]
この出力結果より、要素のfast_nameとprefectureのみを取り出すことができました。