boto3を用いたDynamoDBの操作(1/3)
前回のS3と同様にDynamoDBをbotoライブラリを用いてPythonからAWS APIを操作しました。
nissin-geppox.hatenablog.com
DynamoDBの具体的な操作として、データの読み書きや探索、バックアップなどを行いました。
これらで行った手順と結果をまとめていきます。
今回も以下のコマンドよりダウンロードしたhandsonディレクトリ内のファイルを使用しました。
$ git clone https://github.com/tomomano/learn-aws-by-coding-source-code.git
デプロイ
まず、ローカルにダウンロードしたhandsonディレクトリ内に用意されたファイルを利用するために、以下のコマンドのようにプロジェクトのディレクトリに移動しました。
$ cd learn-aws-by-coding-source-code/handson/dojo/s3
次にvenvを用いて、Pythonの依存ライブラリをインストールしました。
$ python3 -m venv .env $ source .env/bin/activate $ pip install -r requirement.txt
最後にデプロイを行いました。
$ cdk deploy
デプロイに成功するとターミナル上に以下のような出力が表示されます。

ここに表示されている"Cov19VaccinationDb.TableName = "以降に表示されている文字列は以降のコード実行に使用します。
データの読み書き
Jupyter Notebookを用いてプログラムをインタラクティブに実行していきます。
ここでは、データの書き込みや変更、削除を行いました。
以降、実際のコードと出力を示します。
まず、必要なライブラリをインポートし、dynamodbリソースを呼び出しました。
入力
import boto3 from pprint import pprint from datetime import datetime session = boto3.Session(profile_name="default") ddb = session.resource("dynamodb")
次に、テーブル名を格納する変数を定義しました。テーブル名は先ほど表示された文字列を使用しました。
入力
table_name = "Cov19VaccinationDb-Cov19VaccinationTable07030B40-1T7E4C93IZMX3"
table = ddb.Table(table_name)
今回作成するデータベースは”新型コロナウィルスのワクチン接種予約システム”を想定して作成します。
よって、定義する属性はユーザの名前、年齢、住居地、接種回数、予約日時としました。
これらの属性を満たすデータを追加しました。
入力
resp = table.put_item(
Item={
"username": "sazae_huguta",
"first_name": "Sazae",
"last_name": "Huguta",
"age": 24,
"prefecture": "Tokyo",
"dose": 1,
"status": "reserved",
"date": datetime(2021,7,20,hour=10,minute=0).isoformat(timespec="seconds"),
}
)
次に、追加したデータを確認しました。
入力
resp = table.get_item(
Key={"username": "sazae_huguta", "dose": 1}
)
pprint(resp["Item"])
出力
{'age': Decimal('24'),
'date': '2021-07-20T10:00:00',
'dose': Decimal('1'),
'first_name': 'Sazae',
'last_name': 'Huguta',
'prefecture': 'Tokyo',
'status': 'reserved',
'username': 'sazae_huguta'}
この結果より、追加したデータがデータベースに存在することを確認することができました。
次に、要素の内容を変更しました。
入力
resp = table.update_item(
Key={"username": "sazae_huguta", "dose": 1},
UpdateExpression="SET prefecture = :val1",
ExpressionAttributeValues={
":val1": "Aomori",
}
)
さらに、変更した内容を確認しました。
入力
resp = table.get_item(
Key={"username": "sazae_huguta", "dose": 1}
)
pprint(resp["Item"]["prefecture"])
出力
'Aomori'
この出力結果より、正常に要素の内容が変更されたことを確認することができました。
次に、接種状況をresesrvedからcompletedに変更しました。
入力
resp = table.update_item(
Key={"username": "sazae_huguta", "dose": 1},
UpdateExpression="SET #at1 = :val1",
ExpressionAttributeNames={
'#at1': 'status'
},
ExpressionAttributeValues={
":val1": "completed",
}
)
最後に、要素を削除しました。
入力
resp = table.delete_item(
Key={"username": "sazae_huguta", "dose": 1},
)
さらに、要素が削除されたかどうかを確認しました。
入力
resp = table.get_item(
Key={"username": "sazae_huguta", "dose": 1},
)
if resp.get("Item"):
print(resp.get("Item"))
else:
print("The item with the given ID was not found!")
出力
The item with the given ID was not found!
この出力結果より、データベースから要素が削除されたことを確認することができました。
boto3を用いたS3の操作
今回はboto3ライブラリを用いてPythonからAWS APIを操作しました。
S3の具体的な操作として、ローカルのファイルのアップロードやダウンロード、また、これらをメモリから直接行いました。
これらで行った手順と結果をまとめていきます。
今回も以下のコマンドよりダウンロードしたhandsonディレクトリ内のファイルを使用しました。
$ git clone https://github.com/tomomano/learn-aws-by-coding-source-code.git
デプロイ
まず、ローカルにダウンロードしたhandsonディレクトリ内に用意されたファイルを利用するために、以下のコマンドのようにプロジェクトのディレクトリに移動しました。
$ cd learn-aws-by-coding-source-code/handson/dojo/s3
次にvenvを用いて、Pythonの依存ライブラリをインストールしました。
$ python3 -m venv .env $ source .env/bin/activate $ pip install -r requirement.txt
最後にデプロイを行いました。
$ cdk deploy
デプロイに成功するとターミナル上に以下のような出力が表示されます。

ここに表示されている"SimpleS3.BucketName = "以降に表示されている文字列は以降のコード実行に使用します。
ローカル上でのデータの管理
Jupyter Notebookを用いてインタラクティブに実行していきます。
今回はローカルからのアップロードとダウンロードを行いました。
以降、実際のコードと出力を示します。
まず、boto3をインポートし、s3リソースを呼び出しました。
入力
import boto3 session = boto3.Session(profile_name="default") s3 = session.resource("s3")
次に、バケットの名前を格納する変数を作成しました。
バケット名は先ほど表示された文字列を使用します。
入力
bucket_name = "simples3-bucket43879c71-1t7ieflms77lb"
bucket = s3.Bucket(bucket_name)
次にtmp.txtを作成し2種類のキーを設定してアップロードしました。
入力
with open("tmp.txt", "w")as f: f.write("Hello world!") bucket.upload_file("tmp.txt", "myfile1.txt") bucket.upload_file("tmp.txt", "myfile2.txt")
ここで、バケット中のファイルの一覧を表示しました。
入力
objects = bucket.Objects.all() for o in objects: print(o.key)
出力
myfile1.txt myfile2.txt
この出力結果から先ほどアップロードしたファイルを確認することができました。
次にmyfile1.txtオブジェクトを取得し、ファイルのサイズと最終更新日時を表示しました。
入力
obj = bucket.object("myfile1.txt") print(obj.content_length) print(obj.last_modified)
出力
12 2022-05-22 05:47:30+00:00
この出力結果より、ファイルのサイズと最終更新日時を確認することができました。
次に、バケットにあるオブジェクトをローカルにダウンロードしました。
入力
obj.download_file("downloaded.txt")
これによりローカルにオブジェクトをダウンロードすることができました。
最後にオブジェクトを削除し、再びオブジェクトの一覧を表示しました。
入力
obj.delete() objects = bucket.objects.all() for o in objects: print(o.key)
出力
{'ResponseMetadata': {'RequestId': 'MJS4ZZR4RRS8Q3YK',
'HostId': 'Esw+4+hgKgtq5Gao8Q8lQm+BdOlzY9A817Wu6VKXxxJQKP9eT1ACKiBewWniqHymFCsXEcwaVgI=',
'HTTPStatusCode': 204,
'HTTPHeaders': {'x-amz-id-2': 'Esw+4+hgKgtq5Gao8Q8lQm+BdOlzY9A817Wu6VKXxxJQKP9eT1ACKiBewWniqHymFCsXEcwaVgI=',
'x-amz-request-id': 'MJS4ZZR4RRS8Q3YK',
'date': 'Sun, 22 May 2022 05:49:52 GMT',
'server': 'AmazonS3'},
'RetryAttempts': 0}}
myfile2.txt
この出力結果からmyfile1.txtが削除されたことがわかります。
メモリ上でのデータの管理
先ほどまではローカルを経由しデータをやり取りしていましたが、ここではメモリから直接データをアップロード、ダウンロードしました。
また、pandasライブラリを用いてCSVデータと、画像データの読み書きを行いました。
以降、実際のコードと出力を示します。
まず、使用するライブラリをインポートしました。
入力
import pandas as pd import io
次に、pandasを用いてDataFrameオブジェクトを作成しました。
入力
df = pd.DataFrame({'Manufacturer': ["Aston Martin", "Porche", "Ferrari"],
'Top spped (km/h)': [340, 318, 340],
'0-100 km/h (s)': [3.4, 3.4, 2.9],
'Power output (hp)': [715, 510, 710]},
index=['DBS', '911 GT3', 'F8'])
作成した表を出力しました。
入力
df
出力
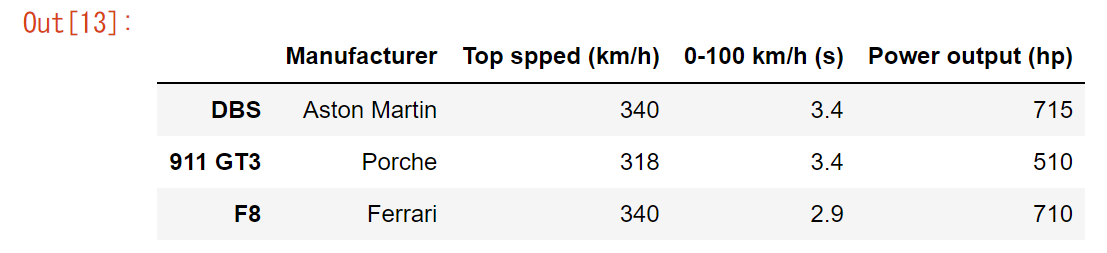
この画像より、表を確認することができました。
続いて、この作成したDataFrameをS3にCSV形式で保存しました。
入力
with io.BytesIO() as stream: df.to_csv(stream, index_label="Car") resp = bucket.put_object( Key="data.csv", Body=stream.getvalue() )
次に、S3にあるCSVデータをメモリ上にロードしました。
入力
obj = bucket.Object("data.csv").get() stream = io.BytesIO(obj.get("Body").read()) df2 = pd.read_csv(stream, index_col="Car")
ここからは画像データの読み書きを行いました。
まず、必要なライブラリをインポートしました。
入力
from PIL import Image import numpy as np from matplotlib import pyplot as plt
次にテスト用の画像をロードしました。
入力
img = Image.open("clownfish.jpg")
また、ロードした画像を表示しました。
入力
plt.imshow(np.asarray(img))
出力

次に、ロードした画像をバケットへアップロードしました。
入力
with io.BytesIO() as buffer:
img.save(buffer, "PNG")
resp = bucket.put_object(
Key="clownfish.png",
Body=buffer.getvalue()
)
ロードが完了したらImageオブジェクトを閉じます。
入力
image.close()
最後にバケットからメモリに直接画像をロードしました。
入力
stream = bucket.Object("clownfish.png").get().get("Body") img2 = Image.open(stream) plt.imshow(np.asarray(img2)) img2.close()
Presigned URL
通常S3のバケットにあるオブジェクトはユーザ自身以外はアクセスすることはできませんが、そのオブジェクトに対してPresigned URLを発行することで、URLを受け取った人物はアクセスすることが可能になります。
ここでは、Presigned URLを発行し、そのオブジェクトに対してダウンロードとアップロードを行いました。
以降、実際のコードと出力を示します。
まず、必要なライブラリをインポートしました。
入力
import requests
続いて、S3にclientオブジェクトを作成しました。
入力
client = session.client("s3")
次に、S3へのアップロードを行うためのPresigned URLを発行しました。
入力
resp = client.generate_presigned_post(
Bucket=bucket.name,
Key="upload.txt",
ExpiresIn=600
)
print(resp)
出力
{'url': 'https://simples3-bucket43879c71-1t7ieflms77lb.s3.amazonaws.com/', 'fields': {'key': 'upload.txt', 'AWSAccessKeyId': 'AKIARLUFVELEK4KE7ZNZ', 'policy': 'eyJleHBpcmF0aW9uIjogIjIwMjItMDUtMjJUMDY6MDg6NDhaIiwgImNvbmRpdGlvbnMiOiBbeyJidWNrZXQiOiAic2ltcGxlczMtYnVja2V0NDM4NzljNzEtMXQ3aWVmbG1zNzdsYiJ9LCB7ImtleSI6ICJ1cGxvYWQudHh0In1dfQ==', 'signature': '/tx2rT7ra3UrwkLahu9ktOBJW/U='}}
この出力結果より、認証情報を確認することができました。
次に、S3へデータをアップロードしました。
入力
resp2 = requests.post(
resp["url"],
data=resp["fields"],
files={'file': ("dummy.text", "Hello world!")}
)
print("Upload success?", resp2.status_code == 204)
出力
Upload success? True
この出力結果より、正常にアップロードされたことを確認することができました。
続いて、S3から特定のオブジェクトをダウンロードするためのPresigned URLを発行しました。
入力
resp3 = client.generate_presigned_url(
ClientMethod='get_object',
Params={
'Bucket': bucket.name,
'Key': "upload.txt",
},
ExpiresIn=600
)
print(resp3)
出力
https://simples3-bucket43879c71-1t7ieflms77lb.s3.amazonaws.com/upload.txt?AWSAccessKeyId=AKIARLUFVELEK4KE7ZNZ&Signature=kde6khq6BF6cJHasVbXSYfEZ9FI%3D&Expires=1653199812
ブラウザからこのURLにアクセスすることによりファイルをダウンロードすることができます。
ダウンロードはコードの実行でも行うことができます。
入力
resp4 = requests.get(resp3) print("Download success?", resp4.status_code == 200) print("File content:", resp4.text)
出力
Download success? True File content: Hello world!
出力結果より、正常にダウンロードされたことを確認することができます。
スタックの削除
スタックの削除は以下のコマンドより行うことができます。
$ cdk destroy
AWS GPUを搭載したEC2インスタンスを用いた行列計算と深層学習(2/2)
前回の行列計算に続いて今回は手書きの数字を識別する深層学習を行いました。
スタックのデプロイやJupyter Notebookの起動などは前回の続きから行うので詳しい準備内容は下記の記事にまとめています。
nissin-geppox.hatenablog.com
テストデータのダウンロード
まず、今回コードを書いていく新しいノートブックと使用するファイルをアップロードしました。
新しいノートブックは"conda_pytorch_p36"で作成し、アップロードするファイルはhandon/mnist/pytorch/ディレクトリ内にある"simple_mnist.py"をアップロードしました。
次に起動したノートブックに必要なライブラリをインポートしました。
入力
import torch import torch.optim as optim import torchvision from torchvision import datasets, transforms from matplotlib import pyplot as plt # custom functions and classes from simple_mnist import Model, train, evaluate
次にテストデータをダウンロードしました。また、画像データの輝度の正規化も行いました。
入力
transf = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transf)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = datasets.MNIST(root='./data', train=False, download=True, transform=transf)
testloader = torch.utils.data.DataLoader(testset, batch_size=1000, shuffle=True)
最後に、ダウンロードした正方形の画像データをいくつか出力しました。
入力
examples = iter(testloader) example_data, example_targets = examples.next() print("Example data size:", example_data.shape) fig = plt.figure(figsize=(10,4)) for i in range(10): plt.subplot(2,5,i+1) plt.tight_layout() plt.imshow(example_data[i][0], cmap='gray', interpolation='none') plt.title("Ground Truth: {}".format(example_targets[i])) plt.xticks([]) plt.yticks([]) plt.show()
出力

この画像より、画像データが正常にダウンロードされたことを確認することができました。
画像の識別
ダウンロードした画像データの数字をCNNを用いて識別しました。
まず、CNNのモデルを定義しました。
入力
model = Model() model.to("cuda") # load to GPU
次にCNNのパラメータを更新する最適化するアルドリズムを定義しました。
入力
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
次にCNNの学習ループを行いました。
入力
train_losses = [] for epoch in range(5): losses = train(model, trainloader, optimizer, epoch) train_losses = train_losses + losses test_loss, test_accuracy = evaluate(model, testloader) print(f"\nTest set: Average loss: {test_loss:.4f}, Accuracy: {test_accuracy:.1f}%\n") plt.figure(figsize=(7,5)) plt.plot(train_losses) plt.xlabel("Iterations") plt.ylabel("Train loss") plt.show()
出力
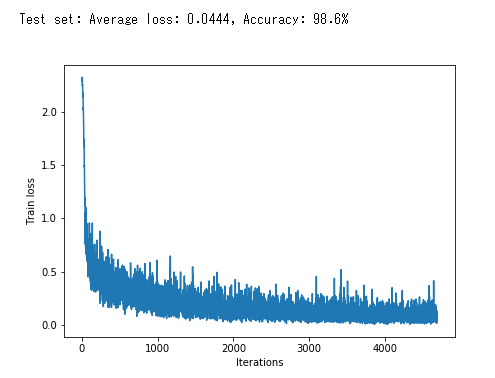
この画像のグラフは損失関数の値の推移を表しています。学習が進むにつれて値は減少していき、最終的な精度は98.6%になることが確認できます。
最後に学習結果を出力しました。
入力
model.eval() with torch.no_grad(): output = model(example_data.to("cuda")) fig = plt.figure(figsize=(10,4)) for i in range(10): plt.subplot(2,5,i+1) plt.tight_layout() plt.imshow(example_data[i][0], cmap='gray', interpolation='none') plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item())) plt.xticks([]) plt.yticks([]) plt.show()
出力

この画像より、出力されたすべての画像が正しく識別されているこを確認することができました。
また、今回学習したニューラルネットワークのパラメータを保存することができます。
入力
torch.save(model.state_dict(), "mnist_cnn.pt")
スタックの削除
スタックの削除は以下のコマンドより行うことができます。
$ cdk destroy
AWS GPUを搭載したEC2インスタンスを用いた行列計算と深層学習(1/2)
今回はEC2のインスタンスタイプ、g4dn.xlargeを用いて行列計算を行いました。
また、深層学習ではCNNを用いて画像に表示された数字を識別しました。
これらで行った手順と結果をまとめていきます。
今回も以下のコマンドよりダウンロードしたhandsonディレクトリ内のファイルを使用しました。
$ git clone https://github.com/tomomano/learn-aws-by-coding-source-code.git
スタックのデプロイ
まず、ローカルにダウンロードしたhandsonフォルダ内に用意されたファイルを利用するために、以下のコマンドのようにプロジェクトのディレクトリに移動しました。
$ cd learn-aws-by-coding-source-code/handson/mnist
次にvenvを用いて、Pythonの依存ライブラリをインストールしました。
$ python3 -m venv .env $ source .env/bin/activate $ pip install -r requirement.txt
また、EC2インスタンスにログインするためのssh鍵を作成しました。
$ export KEY_NAME="HirakeGoma"
$ aws ec2 create-key-pair --key-name ${KEY_NAME} --query 'KeyMaterial' --output text > ${KEY_NAME}.pem
$ mv HirakeGoma.pem ~/.shh/
$ chmod 400 ~/.ssh/HirakeGoma.pem
最後にデプロイを行いました。
$ cdk deploy -c key_name="HirakeGoma"
デプロイに成功するとターミナル上に以下のような出力が表示されます。

ここに表示されている"Ec2ForDI.InstancePublicIp = "以降に表示されているアドレスは以降のコマンド実行に使用します。
ログイン
インタラクティブにコードを実行できるJupyter Notebookを使用するためにトンネル接続でログインしました。
トンネル接続には以下のようにポートフォワーディングのオプションを追加してログインしました。
また、
$ ssh -i ~/.ssh/HirakeGoma.pem -L localhost:8931:localhost:8888 ec2-user@<IP address>
ログインができたら以下のコマンドからg4dn.xlargeインスタンスより、GPUの状態を確認しました。
$ nvidia-smi
これにより、以下のような出力が表示されました。
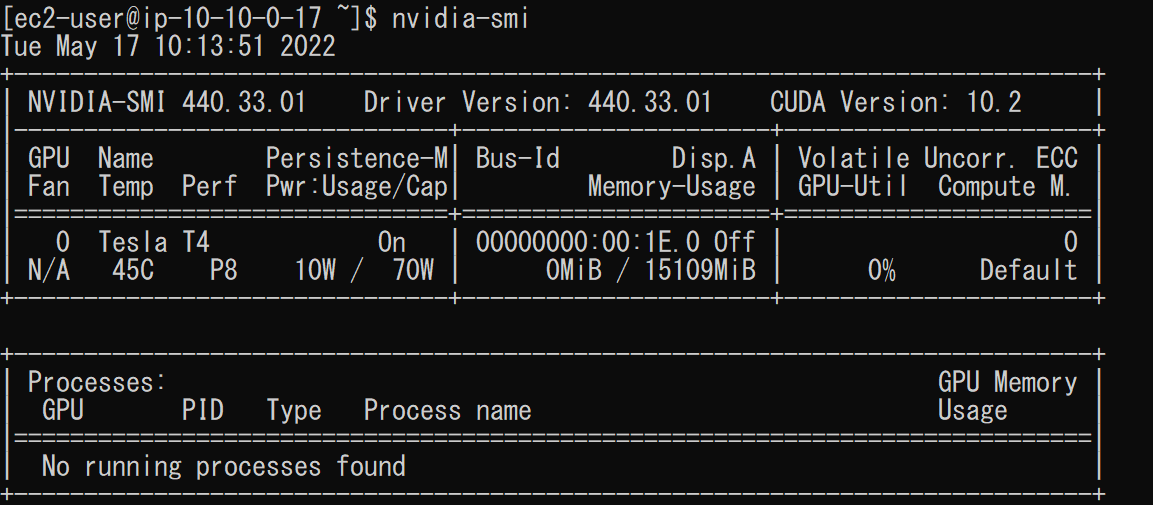
上の画像より、バージョンやメモリの使用率、GPUの負荷などの情報を確認することができました。
Jupyter Notebookの起動
コードをインタラクティブに実行するためにJupyter Notebookを使用します。
今回使用しているDLAMIにはすでにJupyter Notebookがインストールされているので別途インストールする必要はありませんでした。
Jupyter Notebookを起動するには以下のコマンドを使用します。
$ cd ~ $ jupyter notebook
Jupyter Notebookはブラウザ上で操作を行います。
ブラウザからのアクセスは以下の画像の赤下線のアドレスを用いました。
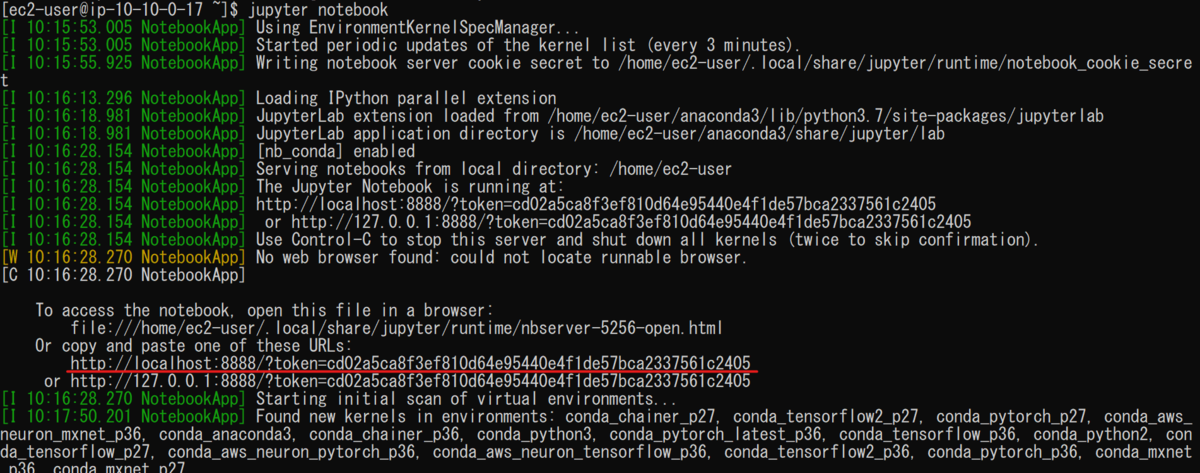
ただし、今回はポートフォワーディングのオプションを設定してるので"http://localhost:8931"を使用する必要があります。
ブラウザからの接続に成功すると以下のような画面が表示されます。
コードの実行
先ほどブラウザ上に起動したJupyter NotebookにPyTorchライブラリをインポートして行列の計算を行いました。
新規ノートブックは"conda_pytorch_p36"を選択し作成しました。
以降、実際のコードと出力を示します。
初めに、PyTorchをインポートし、GPUを使用できる環境にあるかを確認しました。
入力
import torch print("Is CUDA ready?", torch.cuda.is_available())
出力
Is CUDA ready? True
出力結果よりGPUが使用できる環境であることがわかります。
次に、CPU上にランダムな3×3両列を作成しました。
入力
x = torch.rand(3,3) print(x)
出力
tensor([[0.3464, 0.2935, 0.4673], [1.5206, 1.2754, 1.2087], [1.0618, 1.8471, 1.3324]], device='cuda:0')
出力結果よりランダムな3×3行列が作成されたことを確認できます。
次に、GPU上でも行列を作成しました。
入力
y = torch.ones_like(x, device="cuda") x = x.to("cuda")
そして、作成した行列xとyの加算をGPU上で計算しました。
入力
z = x + y
print(z)
出力
tensor([[1.3464, 1.2935, 1.4673], [1.5206, 1.2754, 1.2087], [1.0618, 1.8471, 1.3324]], device='cuda:0')
最後にこの出力結果をCPUに戻しました。
入力
z = z.to("cpu") print(z)
出力
tensor([[1.3464, 1.2935, 1.4673], [1.5206, 1.2754, 1.2087], [1.0618, 1.8471, 1.3324]])
これらの結果よりGPU上で行列の計算が行われたことがわかりました。
10000×10000行列の計算
3×3行列に続いて、高いGPUの計算能力を確認するために、今度は10000×10000行列の計算を行いました。
また、行列の計算はCPUとGPUそれぞれで行い処理速度の違いを比較しました。
まず、CPUで計算を行いました。
入力
s = 10000 device = "cpu" x = torch.rand(s, s, device=device, dtype=torch.float32) y = torch.rand(s, s, device=device, dtype=torch.float32) %time z = torch.matmul(x,y)
出力
CPU time: user 14.3 s, sys: 163 ms, total: 14.5 s Wall time: 7.64s
出力結果より、CPUは7.64sで計算を終えることができました。
次に、GPUで計算を行いました。
入力
s = 10000 device = "cuda" x = torch.rand(s, s, device=device, dtype=torch.float32) y = torch.rand(s, s, device=device, dtype=torch.float32) torch.cuda.synchronize() %time z = torch.matmul(x,y); torch.cuda.synchronize()
出力
CPU times: user 385 ms, sys: 192 ms, total: 577 ms Wall time: 577 ms
出力結果より、GPUは577msで計算を終えることができ、CPUの計算速度に比べ、格段に速いことがわかりました。
AWS APIを用いた俳句アプリケーションの作成
今回はこれまで用いてきたDynamoDBやLambda、S3に加えAPI Gatewayを用いて俳句アプリケーションを作成しました。
nissin-geppox.hatenablog.com
nissin-geppox.hatenablog.com
nissin-geppox.hatenablog.com
また、今回も使用させていただくhandsonフォルダーは以下のコマンドより、ローカルにダウンロードしたものを使用しました。
$ git clone https://github.com/tomomano/learn-aws-by-coding-source-code.git
アプリケーションのデプロイ
まず、ローカルにダウンロードしたhandsonフォルダ内に用意されたファイルを利用するために、以下のコマンドのようにプロジェクトのディレクトリに移動しました。
$ cd learn-aws-by-coding-source-code/handson/bashoutter
次にvenvを用いて、Pythonの依存ライブラリをインストールしました。
$ python3 -m venv .env $ source .env/bin/activate $ pip install -r requirement.txt
最後にデプロイを行いました。
cdk deploy
デプロイに成功するとターミナル上に以下のような出力が表示されます。

ここに表示されている"Bashoutter.BashoutterApiEndpointE9A7B94F = "以降に表示されている文字列は以降のコマンド実行に使用します。
また、"Bashoutter.BucketUrl = "以降の文字列はデプロイしたアプリケーションをGUIで操作する際に必要になります。
AWSコンソール上のAPIには以下のような項目が追加されました。

また、S3のバケットには以下のようなオブジェクトが追加されました。

ターミナルからのAPIリクエストの送信
デプロイしたアプリケーションをターミナル上から操作しました。
まず、先ほど表示された文字列を変数、ENDPOINT_URLに代入しました。
$ export ENDPOINT_URL=<Bashoutter.BashoutterApiEndpointE9A7B94F>
次に、以下のコマンドより俳句の一覧を表示するGET/haikuのAPIを送信しました。
$ http GET "${ENDPOINT_URL}/haiku"
このコマンドにより、以下のようにターミナル上に出力されました。

この画像より、まだ、俳句が要素に追加されていないことがわかります。
よって、以下のコマンドによりPOST/haikuのAPIを用いて俳句を追加しました。
$ http POST "${ENDPOINT_URL}/haiku" \
> username="与謝蕪村" \
> first="春の海" \
> second="ひねもすのたり" \
> third="のたりかな"
このコマンドにより、以下のようにターミナル上に出力されました。
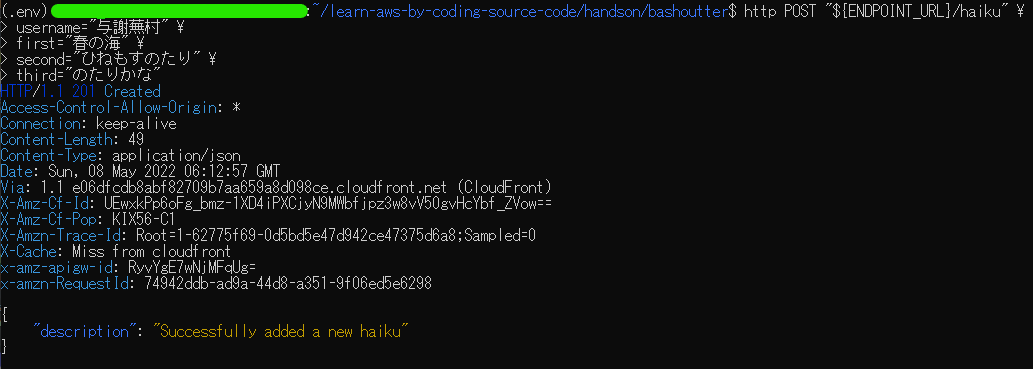
これにより、俳句が追加されたのでGET/haikuのAPIを用いて確認しました。

先ほど追加した俳句が確認できます。
次に、追加した俳句にいいねを追加します。
いいねを追加するには以下のコマンドより、PATCH/haikuのAPIを送信することで行うことができます。
また、コマンド中に入力する
$ http PATCH "${ENDPOINT_URL}/haiku/<item_id>"
このコマンドを用いることで、以下の画像のようにlikesの値が1増加しました。

最後に追加した俳句をDELETE/haikuのAPIを用いることによりデータベースから削除しました。
俳句の削除は以下のコマンドより行うことができます。
$ http DELETE "${ENDPOINT_URL}/haiku/<item_id>"
以下の画像はGET/haikuのAPIを送信した際のターミナル上の出力です。

追加された俳句が削除されていることが確認できます。
大量のAPIリクエストの送信
以下のコマンドより、APIリクエストを300回送信した。
APIリクエストの送信にはhandsonファイル内のclient.pyを使用しました。
$ python client.py $ENDPOINT_URL post_many 300
このコマンドにより、ターミナル上に以下のように出力されました。

この出力が表示されるまでにかかった時間は数秒であり、300回のAPIリクエストが短時間で実行が完了したことを表しています。
これにより、このサーバーレスアプリケーションは多数のユーザによる同時の投稿にも対応することができることがわかりました。
GUIを用いた操作
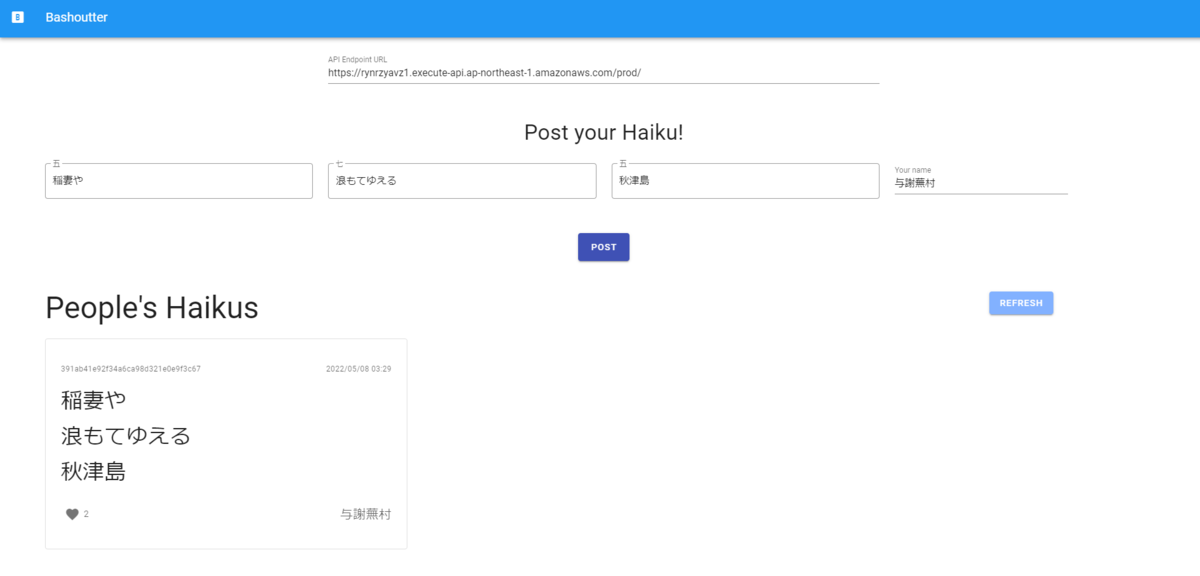
デプロイ成功時に表示された"Bashoutter.BucketUrl = "以降の文字列をウェブブラウザ上に入力することにより、これまで行ってきた操作をGUIを用いて行うことができます。
文字列を入力すると以下のような画面が表示されます。

この画面上で以下のように俳句を追加しました。

追加した俳句はREFRESHをクリックすることにより表示することができます。
また、表示された俳句にいいねを追加することができます。
アプリケーションの削除
アプリケーションの削除は以下のコマンドより行うことができます。
$ cdk destroy
AWS クラウド開発のための環境構築 CDKのインストール
これまで、Docker imageであるtomomano/labcにインストールされていたCDKを利用してきました。
しかし、この環境ではターミナル上に日本語を入力することができませんでした。
よって、今回はCDKをインストールについてまとめます。
npmのインストール
CDKをインストールする前にnpmをインストールします。
npmのインストールは以下のコマンドより行うことができます。
$ sudo apt-get install npm
CDKのインストール
CDKのインストールは以下のコマンドより行うことができます。
また、バージョンは1.100.0をインストールしました。
$ sudo npm install -g aws-cdk@1.100

インストールが正常に行えたかを以下のコマンドを用いて確認しました。
$ cdk --version
![]()
AWSの初期設定
前回のS3の利用の際のエラーはこの設定を行っていなかったために発生しました。
nissin-geppox.hatenablog.com
""cdk bootstrap"のバケット作成は以下のコマンドより行うことができます。
$cdk bootstrap
UbuntuへのGoのインストールと簡単なプログラムの実行
Ubuntu20.04.4 LTSにgo言語をインストールしました。
また、動作確認として簡単なプログラムを実行しました。
Goのインストール
まず、以下のコマンドよりインストールできるバージョンを調べました。
$ apt info golang
ここのバージョンが低い場合には以下のコマンドにより最新にすることができます
$ sudo add-apt-repository ppa:longsleep/golang-backports $ sudo apt-get update
以下のコマンドによりインストールすることができます。
$ sudo apt-get install golang
また、以下のコマンドで正常にインストールできたかどうかを確認しました。
$ go version
![]()
プログラムの作成と実行
まず、以下のコマンドによりディレクトリの作成と移動を行いました。
$ mkdir hello-go $ cd hello-go
次に、このディレクトリ内にプログラムファイル"hello.go"を作成しました。
$sudo vim hello.go
ファイルには以下のようなプログラムを実装しました。
package main import "fmt" func main() { fmt.Println("Hello, World!!") }
また、以下のコマンドよりモジュールを設定します。
$ go mod init hello
最後に、プログラムを実行しました。
$ go run hello.go
結果は以下のようになりました。
![]()
これにより、Goが正常に動作することを確認することができました。