AWS GPUを搭載したEC2インスタンスを用いた行列計算と深層学習(1/2)
今回はEC2のインスタンスタイプ、g4dn.xlargeを用いて行列計算を行いました。
また、深層学習ではCNNを用いて画像に表示された数字を識別しました。
これらで行った手順と結果をまとめていきます。
今回も以下のコマンドよりダウンロードしたhandsonディレクトリ内のファイルを使用しました。
$ git clone https://github.com/tomomano/learn-aws-by-coding-source-code.git
スタックのデプロイ
まず、ローカルにダウンロードしたhandsonフォルダ内に用意されたファイルを利用するために、以下のコマンドのようにプロジェクトのディレクトリに移動しました。
$ cd learn-aws-by-coding-source-code/handson/mnist
次にvenvを用いて、Pythonの依存ライブラリをインストールしました。
$ python3 -m venv .env $ source .env/bin/activate $ pip install -r requirement.txt
また、EC2インスタンスにログインするためのssh鍵を作成しました。
$ export KEY_NAME="HirakeGoma"
$ aws ec2 create-key-pair --key-name ${KEY_NAME} --query 'KeyMaterial' --output text > ${KEY_NAME}.pem
$ mv HirakeGoma.pem ~/.shh/
$ chmod 400 ~/.ssh/HirakeGoma.pem
最後にデプロイを行いました。
$ cdk deploy -c key_name="HirakeGoma"
デプロイに成功するとターミナル上に以下のような出力が表示されます。

ここに表示されている"Ec2ForDI.InstancePublicIp = "以降に表示されているアドレスは以降のコマンド実行に使用します。
ログイン
インタラクティブにコードを実行できるJupyter Notebookを使用するためにトンネル接続でログインしました。
トンネル接続には以下のようにポートフォワーディングのオプションを追加してログインしました。
また、
$ ssh -i ~/.ssh/HirakeGoma.pem -L localhost:8931:localhost:8888 ec2-user@<IP address>
ログインができたら以下のコマンドからg4dn.xlargeインスタンスより、GPUの状態を確認しました。
$ nvidia-smi
これにより、以下のような出力が表示されました。
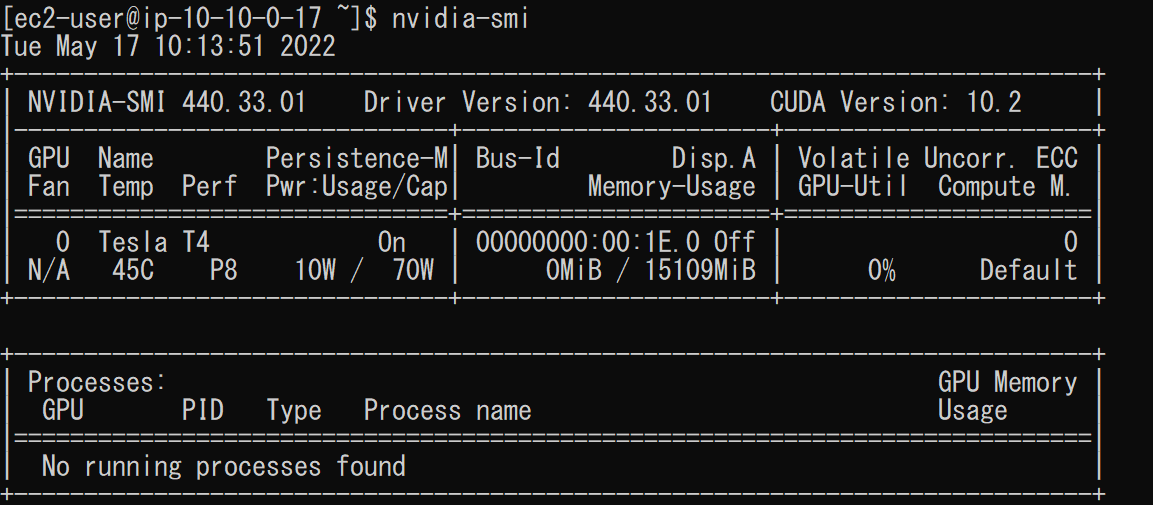
上の画像より、バージョンやメモリの使用率、GPUの負荷などの情報を確認することができました。
Jupyter Notebookの起動
コードをインタラクティブに実行するためにJupyter Notebookを使用します。
今回使用しているDLAMIにはすでにJupyter Notebookがインストールされているので別途インストールする必要はありませんでした。
Jupyter Notebookを起動するには以下のコマンドを使用します。
$ cd ~ $ jupyter notebook
Jupyter Notebookはブラウザ上で操作を行います。
ブラウザからのアクセスは以下の画像の赤下線のアドレスを用いました。
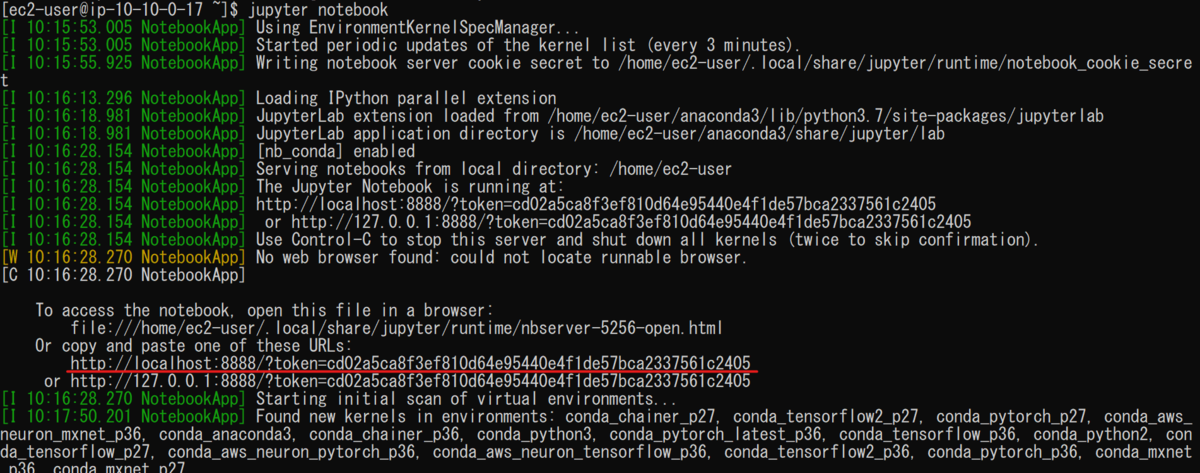
ただし、今回はポートフォワーディングのオプションを設定してるので"http://localhost:8931"を使用する必要があります。
ブラウザからの接続に成功すると以下のような画面が表示されます。
コードの実行
先ほどブラウザ上に起動したJupyter NotebookにPyTorchライブラリをインポートして行列の計算を行いました。
新規ノートブックは"conda_pytorch_p36"を選択し作成しました。
以降、実際のコードと出力を示します。
初めに、PyTorchをインポートし、GPUを使用できる環境にあるかを確認しました。
入力
import torch print("Is CUDA ready?", torch.cuda.is_available())
出力
Is CUDA ready? True
出力結果よりGPUが使用できる環境であることがわかります。
次に、CPU上にランダムな3×3両列を作成しました。
入力
x = torch.rand(3,3) print(x)
出力
tensor([[0.3464, 0.2935, 0.4673], [1.5206, 1.2754, 1.2087], [1.0618, 1.8471, 1.3324]], device='cuda:0')
出力結果よりランダムな3×3行列が作成されたことを確認できます。
次に、GPU上でも行列を作成しました。
入力
y = torch.ones_like(x, device="cuda") x = x.to("cuda")
そして、作成した行列xとyの加算をGPU上で計算しました。
入力
z = x + y
print(z)
出力
tensor([[1.3464, 1.2935, 1.4673], [1.5206, 1.2754, 1.2087], [1.0618, 1.8471, 1.3324]], device='cuda:0')
最後にこの出力結果をCPUに戻しました。
入力
z = z.to("cpu") print(z)
出力
tensor([[1.3464, 1.2935, 1.4673], [1.5206, 1.2754, 1.2087], [1.0618, 1.8471, 1.3324]])
これらの結果よりGPU上で行列の計算が行われたことがわかりました。
10000×10000行列の計算
3×3行列に続いて、高いGPUの計算能力を確認するために、今度は10000×10000行列の計算を行いました。
また、行列の計算はCPUとGPUそれぞれで行い処理速度の違いを比較しました。
まず、CPUで計算を行いました。
入力
s = 10000 device = "cpu" x = torch.rand(s, s, device=device, dtype=torch.float32) y = torch.rand(s, s, device=device, dtype=torch.float32) %time z = torch.matmul(x,y)
出力
CPU time: user 14.3 s, sys: 163 ms, total: 14.5 s Wall time: 7.64s
出力結果より、CPUは7.64sで計算を終えることができました。
次に、GPUで計算を行いました。
入力
s = 10000 device = "cuda" x = torch.rand(s, s, device=device, dtype=torch.float32) y = torch.rand(s, s, device=device, dtype=torch.float32) torch.cuda.synchronize() %time z = torch.matmul(x,y); torch.cuda.synchronize()
出力
CPU times: user 385 ms, sys: 192 ms, total: 577 ms Wall time: 577 ms
出力結果より、GPUは577msで計算を終えることができ、CPUの計算速度に比べ、格段に速いことがわかりました。