boto3を用いたS3の操作
今回はboto3ライブラリを用いてPythonからAWS APIを操作しました。
S3の具体的な操作として、ローカルのファイルのアップロードやダウンロード、また、これらをメモリから直接行いました。
これらで行った手順と結果をまとめていきます。
今回も以下のコマンドよりダウンロードしたhandsonディレクトリ内のファイルを使用しました。
$ git clone https://github.com/tomomano/learn-aws-by-coding-source-code.git
デプロイ
まず、ローカルにダウンロードしたhandsonディレクトリ内に用意されたファイルを利用するために、以下のコマンドのようにプロジェクトのディレクトリに移動しました。
$ cd learn-aws-by-coding-source-code/handson/dojo/s3
次にvenvを用いて、Pythonの依存ライブラリをインストールしました。
$ python3 -m venv .env $ source .env/bin/activate $ pip install -r requirement.txt
最後にデプロイを行いました。
$ cdk deploy
デプロイに成功するとターミナル上に以下のような出力が表示されます。

ここに表示されている"SimpleS3.BucketName = "以降に表示されている文字列は以降のコード実行に使用します。
ローカル上でのデータの管理
Jupyter Notebookを用いてインタラクティブに実行していきます。
今回はローカルからのアップロードとダウンロードを行いました。
以降、実際のコードと出力を示します。
まず、boto3をインポートし、s3リソースを呼び出しました。
入力
import boto3 session = boto3.Session(profile_name="default") s3 = session.resource("s3")
次に、バケットの名前を格納する変数を作成しました。
バケット名は先ほど表示された文字列を使用します。
入力
bucket_name = "simples3-bucket43879c71-1t7ieflms77lb"
bucket = s3.Bucket(bucket_name)
次にtmp.txtを作成し2種類のキーを設定してアップロードしました。
入力
with open("tmp.txt", "w")as f: f.write("Hello world!") bucket.upload_file("tmp.txt", "myfile1.txt") bucket.upload_file("tmp.txt", "myfile2.txt")
ここで、バケット中のファイルの一覧を表示しました。
入力
objects = bucket.Objects.all() for o in objects: print(o.key)
出力
myfile1.txt myfile2.txt
この出力結果から先ほどアップロードしたファイルを確認することができました。
次にmyfile1.txtオブジェクトを取得し、ファイルのサイズと最終更新日時を表示しました。
入力
obj = bucket.object("myfile1.txt") print(obj.content_length) print(obj.last_modified)
出力
12 2022-05-22 05:47:30+00:00
この出力結果より、ファイルのサイズと最終更新日時を確認することができました。
次に、バケットにあるオブジェクトをローカルにダウンロードしました。
入力
obj.download_file("downloaded.txt")
これによりローカルにオブジェクトをダウンロードすることができました。
最後にオブジェクトを削除し、再びオブジェクトの一覧を表示しました。
入力
obj.delete() objects = bucket.objects.all() for o in objects: print(o.key)
出力
{'ResponseMetadata': {'RequestId': 'MJS4ZZR4RRS8Q3YK',
'HostId': 'Esw+4+hgKgtq5Gao8Q8lQm+BdOlzY9A817Wu6VKXxxJQKP9eT1ACKiBewWniqHymFCsXEcwaVgI=',
'HTTPStatusCode': 204,
'HTTPHeaders': {'x-amz-id-2': 'Esw+4+hgKgtq5Gao8Q8lQm+BdOlzY9A817Wu6VKXxxJQKP9eT1ACKiBewWniqHymFCsXEcwaVgI=',
'x-amz-request-id': 'MJS4ZZR4RRS8Q3YK',
'date': 'Sun, 22 May 2022 05:49:52 GMT',
'server': 'AmazonS3'},
'RetryAttempts': 0}}
myfile2.txt
この出力結果からmyfile1.txtが削除されたことがわかります。
メモリ上でのデータの管理
先ほどまではローカルを経由しデータをやり取りしていましたが、ここではメモリから直接データをアップロード、ダウンロードしました。
また、pandasライブラリを用いてCSVデータと、画像データの読み書きを行いました。
以降、実際のコードと出力を示します。
まず、使用するライブラリをインポートしました。
入力
import pandas as pd import io
次に、pandasを用いてDataFrameオブジェクトを作成しました。
入力
df = pd.DataFrame({'Manufacturer': ["Aston Martin", "Porche", "Ferrari"],
'Top spped (km/h)': [340, 318, 340],
'0-100 km/h (s)': [3.4, 3.4, 2.9],
'Power output (hp)': [715, 510, 710]},
index=['DBS', '911 GT3', 'F8'])
作成した表を出力しました。
入力
df
出力
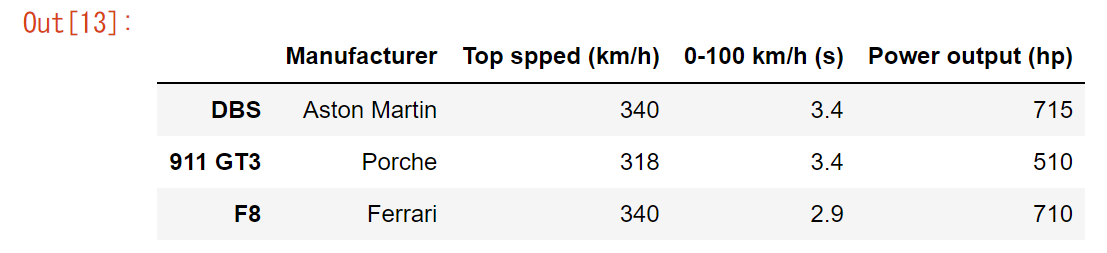
この画像より、表を確認することができました。
続いて、この作成したDataFrameをS3にCSV形式で保存しました。
入力
with io.BytesIO() as stream: df.to_csv(stream, index_label="Car") resp = bucket.put_object( Key="data.csv", Body=stream.getvalue() )
次に、S3にあるCSVデータをメモリ上にロードしました。
入力
obj = bucket.Object("data.csv").get() stream = io.BytesIO(obj.get("Body").read()) df2 = pd.read_csv(stream, index_col="Car")
ここからは画像データの読み書きを行いました。
まず、必要なライブラリをインポートしました。
入力
from PIL import Image import numpy as np from matplotlib import pyplot as plt
次にテスト用の画像をロードしました。
入力
img = Image.open("clownfish.jpg")
また、ロードした画像を表示しました。
入力
plt.imshow(np.asarray(img))
出力

次に、ロードした画像をバケットへアップロードしました。
入力
with io.BytesIO() as buffer:
img.save(buffer, "PNG")
resp = bucket.put_object(
Key="clownfish.png",
Body=buffer.getvalue()
)
ロードが完了したらImageオブジェクトを閉じます。
入力
image.close()
最後にバケットからメモリに直接画像をロードしました。
入力
stream = bucket.Object("clownfish.png").get().get("Body") img2 = Image.open(stream) plt.imshow(np.asarray(img2)) img2.close()
Presigned URL
通常S3のバケットにあるオブジェクトはユーザ自身以外はアクセスすることはできませんが、そのオブジェクトに対してPresigned URLを発行することで、URLを受け取った人物はアクセスすることが可能になります。
ここでは、Presigned URLを発行し、そのオブジェクトに対してダウンロードとアップロードを行いました。
以降、実際のコードと出力を示します。
まず、必要なライブラリをインポートしました。
入力
import requests
続いて、S3にclientオブジェクトを作成しました。
入力
client = session.client("s3")
次に、S3へのアップロードを行うためのPresigned URLを発行しました。
入力
resp = client.generate_presigned_post(
Bucket=bucket.name,
Key="upload.txt",
ExpiresIn=600
)
print(resp)
出力
{'url': 'https://simples3-bucket43879c71-1t7ieflms77lb.s3.amazonaws.com/', 'fields': {'key': 'upload.txt', 'AWSAccessKeyId': 'AKIARLUFVELEK4KE7ZNZ', 'policy': 'eyJleHBpcmF0aW9uIjogIjIwMjItMDUtMjJUMDY6MDg6NDhaIiwgImNvbmRpdGlvbnMiOiBbeyJidWNrZXQiOiAic2ltcGxlczMtYnVja2V0NDM4NzljNzEtMXQ3aWVmbG1zNzdsYiJ9LCB7ImtleSI6ICJ1cGxvYWQudHh0In1dfQ==', 'signature': '/tx2rT7ra3UrwkLahu9ktOBJW/U='}}
この出力結果より、認証情報を確認することができました。
次に、S3へデータをアップロードしました。
入力
resp2 = requests.post(
resp["url"],
data=resp["fields"],
files={'file': ("dummy.text", "Hello world!")}
)
print("Upload success?", resp2.status_code == 204)
出力
Upload success? True
この出力結果より、正常にアップロードされたことを確認することができました。
続いて、S3から特定のオブジェクトをダウンロードするためのPresigned URLを発行しました。
入力
resp3 = client.generate_presigned_url(
ClientMethod='get_object',
Params={
'Bucket': bucket.name,
'Key': "upload.txt",
},
ExpiresIn=600
)
print(resp3)
出力
https://simples3-bucket43879c71-1t7ieflms77lb.s3.amazonaws.com/upload.txt?AWSAccessKeyId=AKIARLUFVELEK4KE7ZNZ&Signature=kde6khq6BF6cJHasVbXSYfEZ9FI%3D&Expires=1653199812
ブラウザからこのURLにアクセスすることによりファイルをダウンロードすることができます。
ダウンロードはコードの実行でも行うことができます。
入力
resp4 = requests.get(resp3) print("Download success?", resp4.status_code == 200) print("File content:", resp4.text)
出力
Download success? True File content: Hello world!
出力結果より、正常にダウンロードされたことを確認することができます。
スタックの削除
スタックの削除は以下のコマンドより行うことができます。
$ cdk destroy